Article
How to Scale Jira Product Discovery
The Hidden Limits of Jira Product Discovery (And How to Engineer Around Them)


The introduction of Jira Product Discovery (JPD) represented a paradigm shift in the Atlassian ecosystem. It finally acknowledged that the work of a product manager begins long before a ticket enters a sprint. By formalizing the "upstream" process of ideation and prioritization, Atlassian provided a dedicated environment where uncertainty could be managed without cluttering delivery backlogs.
For many, the transition from fragmented spreadsheets to a native Jira environment felt like a major win for workflow continuity. However, as organizations scale their usage, they frequently encounter a series of rigid technical boundaries. These aren't just minor bugs; they are architectural idiosyncrasies—ranging from hard data caps to "invisible" formula fields—that dictate how a sustainable, enterprise-grade discovery engine must be built.
How does the team-managed architecture affect data visibility?
At its core, JPD is built upon the team-managed project framework. This was an intentional choice designed to grant product teams maximum autonomy over their workflows and custom fields without requiring constant intervention from Jira admins.
While this autonomy facilitates rapid iteration, it introduces a systemic decoupling from the broader Jira platform. JPD introduces entirely new field types—such as formula fields and delivery progress indicators—built on a modern architecture outside the legacy Jira issue schema.
The Fragmented User Experience
Because these fields are not part of the standard Jira schema, they frequently fail to render when an "Idea" is accessed through global Jira features like Advanced Issue Search or standard dashboard gadgets. When a stakeholder opens an Idea from a filter results list, the sophisticated JPD fields often disappear, replaced by a generic view that excludes insights and formatted scores. This creates a situation where the "source of truth" is only fully visible within the confines of the JPD project itself.
The Hierarchy Gap
At the issue level, the connection between JPD and Jira Software appears deceptively smooth. From any Idea, you can create or link Epics, Stories, and Tasks, viewing the delivery work in the dedicated "Delivery" tab. However, this integration is essentially skin-deep.
As soon as you attempt to visualize this work in Advanced Roadmaps (Plans), the architecture falters. Because JPD projects are team-managed, Ideas cannot be integrated into the global Jira hierarchy (Themes → Initiatives → Epics → Stories). Instead of sitting at the top as the strategic "parent," JPD Ideas often appear as plain stories or flat objects, breaking the top-down traceability that Product Operations requires.
This is a significant structural miss: product teams want Ideas to sit at the absolute peak of the hierarchy, providing a single source of truth for dates, ownership, and progress across all downstream work. Currently, PMs are forced to jump between JPD views and Plans to manually reconstruct the "big picture." If you believe Atlassian needs to prioritize a unified hierarchy on their roadmap, you are certainly not alone in that frustration.
What are the hard limits for JPD entities?
Product discovery is inherently data-intensive. A single strategic initiative might be supported by hundreds of customer quotes and support tickets, all captured as "Insights." In a mature organization, these accumulate rapidly, eventually hitting the "glass ceiling" of Atlassian’s cloud guardrails.
Technical Entity Limits and Operational Impact
Entity Type | Maximum Limit | Operational Implication |
Ideas per Project | 5,000 | Forces aggressive archiving to maintain project performance. |
Insights per Project | 10,000 | The most critical ceiling; blocks further evidence collection once reached. |
Insights per Idea | 2,000 | Limits the amount of qualitative data aggregated under one opportunity. |
Vote Fields per Project | 100 | Restricts unique prioritization rounds or stakeholder groups over time. |
Fields per Project | 200 | Caps the complexity of custom prioritization metadata. |
The limit of 10,000 insights is particularly problematic for teams using JPD as a centralized research repository. When this threshold is crossed, users receive a "limit reached" error that can paralyze a discovery cycle. While archiving ideas is the suggested remediation, it is essentially a form of forced data loss for active projects.
Why don’t JPD formulas work with Jira Automation?
Prioritization is the heartbeat of product management, and JPD allows teams to create sophisticated scoring models using custom formulas. For example, a team might use a RICE framework to calculate priority:
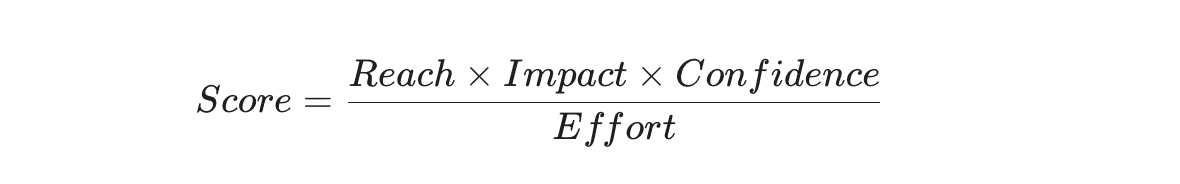
These formulas are powerful for visualization, but they have a major technical caveat: the resulting values are "transient." They are calculated and displayed in the user interface, but they are not physically stored as persistent data in the database.
Think of it like this: A JPD formula field is a high-definition projector. It shows you the result on the screen so you can discuss it, but it doesn't print the number onto the underlying paper record.
The Automation Blind Spot
Because the data isn't "stored," the Jira automation engine and Jira Query Language (JQL) cannot see the results. This leads to several operational failures:
No Triggers: You cannot trigger an automation rule based on a formula field change.
No Filtering: You cannot use JQL to find "all ideas with a score greater than 50" for external reporting.
Stale Data: If a field was a static number before being converted to a formula, the automation engine may continue to use the old, stale value.
How can you mitigate the "Voting Paradox"?
JPD’s "Vote" field is designed to democratize prioritization. However, the technical implementation carries a hidden constraint: a vote field is functionally limited to a single round. There is no native way to "reset" the field for a new quarter without deleting the historical data.
To conduct a second round of voting while preserving the first, you must create an entirely new vote field. Given the 100-vote field limit, a team conducting quarterly voting across multiple departments could reach this limit in just a few years. Furthermore, since vote fields don't support automation, a shift in stakeholder sentiment cannot automatically trigger a status transition or a Slack alert, forcing PMs back into manual coordination.
What are the engineering workarounds for Automation?
To restore functionality, expert users often bypass the JPD formula UI and replicate logic using Jira Automation and smart values. This involves creating a dedicated, static "Number" field that mirrors the intended formula.
The Trigger: The automation listens for changes in input fields (e.g., Reach or Effort).
The Calculation: The rule uses smart values to perform the math. For complex logic, like finding the maximum value between two fields, users must use syntax like
{{#=}}Max({{field_1}}, {{field_2}}){{/}}.The Persistence: The result is saved into the static Number field, which is visible to JQL.
The Cost of Complexity: This approach consumes significant automation run quotas. On a Standard plan (capped at 500 runs/month), a high-volume project can exhaust its allowance in days. This creates a "pay-to-play" barrier where advanced product operations must eventually move to the Premium tier.
The External Sharing Barrier and Stakeholder Friction
Jira Product Discovery is a collaborative tool, yet its "External Sharing" capabilities often fall short of stakeholder expectations for a frictionless experience.
The Atlassian Account Requirement
The primary point of friction is the mandatory requirement for stakeholders to create an Atlassian account to access "Published Views." Even though these users don't consume a paid license, the login process is a hurdle for senior leadership or external customers.
Missing Data in Published Views
Many critical fields are simply not supported in JPD's native published views:
Formula Fields: Stakeholders cannot see the calculated priority scores.
Vote Fields: Internal sentiment and stakeholder heatmaps are hidden.
Insights Count: The "weight of evidence" supporting an idea cannot be visualized.
This creates a one-way communication channel that often forces product teams back into secondary tools like Slack or slide decks to present their work.
Scaling Product Operations with Released
The inherent limitations of JPD—the data caps, the automation blind spots, and the high-friction sharing—create a ceiling for scaling organizations. This is where Released emerges as critical infrastructure, transforming JPD from an internal planning tool into a comprehensive communication hub.
Solving the Branding and Access Gap
Released addresses the sharing limitation by providing a branded presentation layer. While JPD's native sharing is locked behind a login, Released allows teams to create product roadmaps that can be public or restricted by domain—without requiring stakeholders to navigate the Atlassian sign-up process.
Closing the Feedback Loop
A recurring pain point in product operations is "closing the loop"—notifying the users who requested a feature once it has shipped. Released solves this by providing a feedback inbox that links directly to JPD ideas. When a feature is moved to "Done," the system can help you generate release notes and notify the original requesters, turning customers into advocates.
AI-Powered Communication
The administrative burden of writing updates is reduced through AI. By scanning JPD ideas and linked Jira Software tickets, Released can generate professional announcements 10x faster than manual drafting. This ensures the product team spends less time on documentation and more time on high-value discovery.
Summary
JPD is a pioneering tool for structuring the chaotic realm of ideation. For small teams, its native features provide a massive leap forward. However, for the enterprise, the "hidden limits" represent a significant challenge.
If you remember one thing, make it this: Use Jira Product Discovery to manage the internal "why" and data-heavy research, but decouple your communication by using a specialized platform like Released to engage your stakeholders.
By engineering around the technical limits of the Atlassian ecosystem, product teams can ensure their discovery engine remains focused on solving customer problems rather than managing administrative workarounds.
Article
How to Scale Jira Product Discovery
The Hidden Limits of Jira Product Discovery (And How to Engineer Around Them)
The introduction of Jira Product Discovery (JPD) represented a paradigm shift in the Atlassian ecosystem. It finally acknowledged that the work of a product manager begins long before a ticket enters a sprint. By formalizing the "upstream" process of ideation and prioritization, Atlassian provided a dedicated environment where uncertainty could be managed without cluttering delivery backlogs.
For many, the transition from fragmented spreadsheets to a native Jira environment felt like a major win for workflow continuity. However, as organizations scale their usage, they frequently encounter a series of rigid technical boundaries. These aren't just minor bugs; they are architectural idiosyncrasies—ranging from hard data caps to "invisible" formula fields—that dictate how a sustainable, enterprise-grade discovery engine must be built.
How does the team-managed architecture affect data visibility?
At its core, JPD is built upon the team-managed project framework. This was an intentional choice designed to grant product teams maximum autonomy over their workflows and custom fields without requiring constant intervention from Jira admins.
While this autonomy facilitates rapid iteration, it introduces a systemic decoupling from the broader Jira platform. JPD introduces entirely new field types—such as formula fields and delivery progress indicators—built on a modern architecture outside the legacy Jira issue schema.
The Fragmented User Experience
Because these fields are not part of the standard Jira schema, they frequently fail to render when an "Idea" is accessed through global Jira features like Advanced Issue Search or standard dashboard gadgets. When a stakeholder opens an Idea from a filter results list, the sophisticated JPD fields often disappear, replaced by a generic view that excludes insights and formatted scores. This creates a situation where the "source of truth" is only fully visible within the confines of the JPD project itself.
The Hierarchy Gap
At the issue level, the connection between JPD and Jira Software appears deceptively smooth. From any Idea, you can create or link Epics, Stories, and Tasks, viewing the delivery work in the dedicated "Delivery" tab. However, this integration is essentially skin-deep.
As soon as you attempt to visualize this work in Advanced Roadmaps (Plans), the architecture falters. Because JPD projects are team-managed, Ideas cannot be integrated into the global Jira hierarchy (Themes → Initiatives → Epics → Stories). Instead of sitting at the top as the strategic "parent," JPD Ideas often appear as plain stories or flat objects, breaking the top-down traceability that Product Operations requires.
This is a significant structural miss: product teams want Ideas to sit at the absolute peak of the hierarchy, providing a single source of truth for dates, ownership, and progress across all downstream work. Currently, PMs are forced to jump between JPD views and Plans to manually reconstruct the "big picture." If you believe Atlassian needs to prioritize a unified hierarchy on their roadmap, you are certainly not alone in that frustration.
What are the hard limits for JPD entities?
Product discovery is inherently data-intensive. A single strategic initiative might be supported by hundreds of customer quotes and support tickets, all captured as "Insights." In a mature organization, these accumulate rapidly, eventually hitting the "glass ceiling" of Atlassian’s cloud guardrails.
Technical Entity Limits and Operational Impact
Entity Type | Maximum Limit | Operational Implication |
Ideas per Project | 5,000 | Forces aggressive archiving to maintain project performance. |
Insights per Project | 10,000 | The most critical ceiling; blocks further evidence collection once reached. |
Insights per Idea | 2,000 | Limits the amount of qualitative data aggregated under one opportunity. |
Vote Fields per Project | 100 | Restricts unique prioritization rounds or stakeholder groups over time. |
Fields per Project | 200 | Caps the complexity of custom prioritization metadata. |
The limit of 10,000 insights is particularly problematic for teams using JPD as a centralized research repository. When this threshold is crossed, users receive a "limit reached" error that can paralyze a discovery cycle. While archiving ideas is the suggested remediation, it is essentially a form of forced data loss for active projects.
Why don’t JPD formulas work with Jira Automation?
Prioritization is the heartbeat of product management, and JPD allows teams to create sophisticated scoring models using custom formulas. For example, a team might use a RICE framework to calculate priority:
These formulas are powerful for visualization, but they have a major technical caveat: the resulting values are "transient." They are calculated and displayed in the user interface, but they are not physically stored as persistent data in the database.
Think of it like this: A JPD formula field is a high-definition projector. It shows you the result on the screen so you can discuss it, but it doesn't print the number onto the underlying paper record.
The Automation Blind Spot
Because the data isn't "stored," the Jira automation engine and Jira Query Language (JQL) cannot see the results. This leads to several operational failures:
No Triggers: You cannot trigger an automation rule based on a formula field change.
No Filtering: You cannot use JQL to find "all ideas with a score greater than 50" for external reporting.
Stale Data: If a field was a static number before being converted to a formula, the automation engine may continue to use the old, stale value.
How can you mitigate the "Voting Paradox"?
JPD’s "Vote" field is designed to democratize prioritization. However, the technical implementation carries a hidden constraint: a vote field is functionally limited to a single round. There is no native way to "reset" the field for a new quarter without deleting the historical data.
To conduct a second round of voting while preserving the first, you must create an entirely new vote field. Given the 100-vote field limit, a team conducting quarterly voting across multiple departments could reach this limit in just a few years. Furthermore, since vote fields don't support automation, a shift in stakeholder sentiment cannot automatically trigger a status transition or a Slack alert, forcing PMs back into manual coordination.
What are the engineering workarounds for Automation?
To restore functionality, expert users often bypass the JPD formula UI and replicate logic using Jira Automation and smart values. This involves creating a dedicated, static "Number" field that mirrors the intended formula.
The Trigger: The automation listens for changes in input fields (e.g., Reach or Effort).
The Calculation: The rule uses smart values to perform the math. For complex logic, like finding the maximum value between two fields, users must use syntax like
{{#=}}Max({{field_1}}, {{field_2}}){{/}}.The Persistence: The result is saved into the static Number field, which is visible to JQL.
The Cost of Complexity: This approach consumes significant automation run quotas. On a Standard plan (capped at 500 runs/month), a high-volume project can exhaust its allowance in days. This creates a "pay-to-play" barrier where advanced product operations must eventually move to the Premium tier.
The External Sharing Barrier and Stakeholder Friction
Jira Product Discovery is a collaborative tool, yet its "External Sharing" capabilities often fall short of stakeholder expectations for a frictionless experience.
The Atlassian Account Requirement
The primary point of friction is the mandatory requirement for stakeholders to create an Atlassian account to access "Published Views." Even though these users don't consume a paid license, the login process is a hurdle for senior leadership or external customers.
Missing Data in Published Views
Many critical fields are simply not supported in JPD's native published views:
Formula Fields: Stakeholders cannot see the calculated priority scores.
Vote Fields: Internal sentiment and stakeholder heatmaps are hidden.
Insights Count: The "weight of evidence" supporting an idea cannot be visualized.
This creates a one-way communication channel that often forces product teams back into secondary tools like Slack or slide decks to present their work.
Scaling Product Operations with Released
The inherent limitations of JPD—the data caps, the automation blind spots, and the high-friction sharing—create a ceiling for scaling organizations. This is where Released emerges as critical infrastructure, transforming JPD from an internal planning tool into a comprehensive communication hub.
Solving the Branding and Access Gap
Released addresses the sharing limitation by providing a branded presentation layer. While JPD's native sharing is locked behind a login, Released allows teams to create product roadmaps that can be public or restricted by domain—without requiring stakeholders to navigate the Atlassian sign-up process.
Closing the Feedback Loop
A recurring pain point in product operations is "closing the loop"—notifying the users who requested a feature once it has shipped. Released solves this by providing a feedback inbox that links directly to JPD ideas. When a feature is moved to "Done," the system can help you generate release notes and notify the original requesters, turning customers into advocates.
AI-Powered Communication
The administrative burden of writing updates is reduced through AI. By scanning JPD ideas and linked Jira Software tickets, Released can generate professional announcements 10x faster than manual drafting. This ensures the product team spends less time on documentation and more time on high-value discovery.
Summary
JPD is a pioneering tool for structuring the chaotic realm of ideation. For small teams, its native features provide a massive leap forward. However, for the enterprise, the "hidden limits" represent a significant challenge.
If you remember one thing, make it this: Use Jira Product Discovery to manage the internal "why" and data-heavy research, but decouple your communication by using a specialized platform like Released to engage your stakeholders.
By engineering around the technical limits of the Atlassian ecosystem, product teams can ensure their discovery engine remains focused on solving customer problems rather than managing administrative workarounds.
Article
How to Scale Jira Product Discovery
The Hidden Limits of Jira Product Discovery (And How to Engineer Around Them)
The introduction of Jira Product Discovery (JPD) represented a paradigm shift in the Atlassian ecosystem. It finally acknowledged that the work of a product manager begins long before a ticket enters a sprint. By formalizing the "upstream" process of ideation and prioritization, Atlassian provided a dedicated environment where uncertainty could be managed without cluttering delivery backlogs.
For many, the transition from fragmented spreadsheets to a native Jira environment felt like a major win for workflow continuity. However, as organizations scale their usage, they frequently encounter a series of rigid technical boundaries. These aren't just minor bugs; they are architectural idiosyncrasies—ranging from hard data caps to "invisible" formula fields—that dictate how a sustainable, enterprise-grade discovery engine must be built.
How does the team-managed architecture affect data visibility?
At its core, JPD is built upon the team-managed project framework. This was an intentional choice designed to grant product teams maximum autonomy over their workflows and custom fields without requiring constant intervention from Jira admins.
While this autonomy facilitates rapid iteration, it introduces a systemic decoupling from the broader Jira platform. JPD introduces entirely new field types—such as formula fields and delivery progress indicators—built on a modern architecture outside the legacy Jira issue schema.
The Fragmented User Experience
Because these fields are not part of the standard Jira schema, they frequently fail to render when an "Idea" is accessed through global Jira features like Advanced Issue Search or standard dashboard gadgets. When a stakeholder opens an Idea from a filter results list, the sophisticated JPD fields often disappear, replaced by a generic view that excludes insights and formatted scores. This creates a situation where the "source of truth" is only fully visible within the confines of the JPD project itself.
The Hierarchy Gap
At the issue level, the connection between JPD and Jira Software appears deceptively smooth. From any Idea, you can create or link Epics, Stories, and Tasks, viewing the delivery work in the dedicated "Delivery" tab. However, this integration is essentially skin-deep.
As soon as you attempt to visualize this work in Advanced Roadmaps (Plans), the architecture falters. Because JPD projects are team-managed, Ideas cannot be integrated into the global Jira hierarchy (Themes → Initiatives → Epics → Stories). Instead of sitting at the top as the strategic "parent," JPD Ideas often appear as plain stories or flat objects, breaking the top-down traceability that Product Operations requires.
This is a significant structural miss: product teams want Ideas to sit at the absolute peak of the hierarchy, providing a single source of truth for dates, ownership, and progress across all downstream work. Currently, PMs are forced to jump between JPD views and Plans to manually reconstruct the "big picture." If you believe Atlassian needs to prioritize a unified hierarchy on their roadmap, you are certainly not alone in that frustration.
What are the hard limits for JPD entities?
Product discovery is inherently data-intensive. A single strategic initiative might be supported by hundreds of customer quotes and support tickets, all captured as "Insights." In a mature organization, these accumulate rapidly, eventually hitting the "glass ceiling" of Atlassian’s cloud guardrails.
Technical Entity Limits and Operational Impact
Entity Type | Maximum Limit | Operational Implication |
Ideas per Project | 5,000 | Forces aggressive archiving to maintain project performance. |
Insights per Project | 10,000 | The most critical ceiling; blocks further evidence collection once reached. |
Insights per Idea | 2,000 | Limits the amount of qualitative data aggregated under one opportunity. |
Vote Fields per Project | 100 | Restricts unique prioritization rounds or stakeholder groups over time. |
Fields per Project | 200 | Caps the complexity of custom prioritization metadata. |
The limit of 10,000 insights is particularly problematic for teams using JPD as a centralized research repository. When this threshold is crossed, users receive a "limit reached" error that can paralyze a discovery cycle. While archiving ideas is the suggested remediation, it is essentially a form of forced data loss for active projects.
Why don’t JPD formulas work with Jira Automation?
Prioritization is the heartbeat of product management, and JPD allows teams to create sophisticated scoring models using custom formulas. For example, a team might use a RICE framework to calculate priority:
These formulas are powerful for visualization, but they have a major technical caveat: the resulting values are "transient." They are calculated and displayed in the user interface, but they are not physically stored as persistent data in the database.
Think of it like this: A JPD formula field is a high-definition projector. It shows you the result on the screen so you can discuss it, but it doesn't print the number onto the underlying paper record.
The Automation Blind Spot
Because the data isn't "stored," the Jira automation engine and Jira Query Language (JQL) cannot see the results. This leads to several operational failures:
No Triggers: You cannot trigger an automation rule based on a formula field change.
No Filtering: You cannot use JQL to find "all ideas with a score greater than 50" for external reporting.
Stale Data: If a field was a static number before being converted to a formula, the automation engine may continue to use the old, stale value.
How can you mitigate the "Voting Paradox"?
JPD’s "Vote" field is designed to democratize prioritization. However, the technical implementation carries a hidden constraint: a vote field is functionally limited to a single round. There is no native way to "reset" the field for a new quarter without deleting the historical data.
To conduct a second round of voting while preserving the first, you must create an entirely new vote field. Given the 100-vote field limit, a team conducting quarterly voting across multiple departments could reach this limit in just a few years. Furthermore, since vote fields don't support automation, a shift in stakeholder sentiment cannot automatically trigger a status transition or a Slack alert, forcing PMs back into manual coordination.
What are the engineering workarounds for Automation?
To restore functionality, expert users often bypass the JPD formula UI and replicate logic using Jira Automation and smart values. This involves creating a dedicated, static "Number" field that mirrors the intended formula.
The Trigger: The automation listens for changes in input fields (e.g., Reach or Effort).
The Calculation: The rule uses smart values to perform the math. For complex logic, like finding the maximum value between two fields, users must use syntax like
{{#=}}Max({{field_1}}, {{field_2}}){{/}}.The Persistence: The result is saved into the static Number field, which is visible to JQL.
The Cost of Complexity: This approach consumes significant automation run quotas. On a Standard plan (capped at 500 runs/month), a high-volume project can exhaust its allowance in days. This creates a "pay-to-play" barrier where advanced product operations must eventually move to the Premium tier.
The External Sharing Barrier and Stakeholder Friction
Jira Product Discovery is a collaborative tool, yet its "External Sharing" capabilities often fall short of stakeholder expectations for a frictionless experience.
The Atlassian Account Requirement
The primary point of friction is the mandatory requirement for stakeholders to create an Atlassian account to access "Published Views." Even though these users don't consume a paid license, the login process is a hurdle for senior leadership or external customers.
Missing Data in Published Views
Many critical fields are simply not supported in JPD's native published views:
Formula Fields: Stakeholders cannot see the calculated priority scores.
Vote Fields: Internal sentiment and stakeholder heatmaps are hidden.
Insights Count: The "weight of evidence" supporting an idea cannot be visualized.
This creates a one-way communication channel that often forces product teams back into secondary tools like Slack or slide decks to present their work.
Scaling Product Operations with Released
The inherent limitations of JPD—the data caps, the automation blind spots, and the high-friction sharing—create a ceiling for scaling organizations. This is where Released emerges as critical infrastructure, transforming JPD from an internal planning tool into a comprehensive communication hub.
Solving the Branding and Access Gap
Released addresses the sharing limitation by providing a branded presentation layer. While JPD's native sharing is locked behind a login, Released allows teams to create product roadmaps that can be public or restricted by domain—without requiring stakeholders to navigate the Atlassian sign-up process.
Closing the Feedback Loop
A recurring pain point in product operations is "closing the loop"—notifying the users who requested a feature once it has shipped. Released solves this by providing a feedback inbox that links directly to JPD ideas. When a feature is moved to "Done," the system can help you generate release notes and notify the original requesters, turning customers into advocates.
AI-Powered Communication
The administrative burden of writing updates is reduced through AI. By scanning JPD ideas and linked Jira Software tickets, Released can generate professional announcements 10x faster than manual drafting. This ensures the product team spends less time on documentation and more time on high-value discovery.
Summary
JPD is a pioneering tool for structuring the chaotic realm of ideation. For small teams, its native features provide a massive leap forward. However, for the enterprise, the "hidden limits" represent a significant challenge.
If you remember one thing, make it this: Use Jira Product Discovery to manage the internal "why" and data-heavy research, but decouple your communication by using a specialized platform like Released to engage your stakeholders.
By engineering around the technical limits of the Atlassian ecosystem, product teams can ensure their discovery engine remains focused on solving customer problems rather than managing administrative workarounds.
Use cases
Resources
Backed by


Use cases
Backed by
Use cases
Resources
Backed by